由 Jina AI 训练的文本嵌入模型集。
快速开始
开始使用 jina-embeddings-v2-base-en 最简单的方法是使用 Jina AI 的 Embedding API。
预期用途与模型信息
jina-embeddings-v2-base-en 是一款英语单语种嵌入模型,支持8192序列长度。
它基于 BERT 架构(JinaBERT),该架构支持 ALiBi 的对称双向变体,以实现更长的序列长度。
其基础模型 jina-bert-v2-base-en 在 C4 数据集上进行了预训练。
该模型在 Jina AI 收集的超过 4 亿个句子对和难负样本上进一步训练。
这些句子对来源于不同领域,并经过严格的清洗流程精心筛选。
该嵌入模型在训练时采用 512 序列长度,但借助 ALiBi 技术可外推至 8k 序列长度(甚至更长)。 这使得我们的模型适用于多种使用场景,尤其在需要处理长文档时,包括长文档检索、语义文本相似度、文本重排序、推荐系统、RAG 以及基于 LLM 的生成式搜索等。
该模型标准参数规模为 1.37 亿,在提供比小型模型更优性能的同时,仍能实现快速推理。建议使用单 GPU 进行推理。 此外,我们还提供以下嵌入模型:
数据与参数
Jina Embeddings V2 技术报告
使用方法
集成模型时请应用均值池化(mean pooling)。
为何使用均值池化?
均值池化 从模型输出中获取所有 token 嵌入,并在句子/段落级别对它们进行平均。
事实证明,这是生成高质量句子嵌入最有效的方法。
我们提供了一个 encode 函数来处理此过程。
不过,若您希望不使用默认的 encode 函数来实现:
# coding = utf-8
import os
import torch
import torch_npu
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import argparse
from openmind import pipeline, is_torch_npu_available
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument("--model_name_or_path", type=str, default="./")
args = parser.parse_args()
model_path = args.model_name_or_path
device = None
if is_torch_npu_available():
device = "npu:0"
else:
device = "cpu"
model = SentenceTransformer(model_path)
model = model.to(device)
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
cosine_scores = cos_sim(embeddings[0], embeddings[1])
print(f"cosine_scores: {cosine_scores}")使用其最新版本(v2.3.0)的 sentence-transformers 也支持 Jina 嵌入(请确保你也已登录 ):
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-en", # switch to en/zh for English or Chinese
trust_remote_code=True
)
# control your input sequence length up to 8192
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'What is the current weather like today?'
])
print(cos_sim(embeddings[0], embeddings[1]))使用 Transformers(或 SentencTransformers)包的替代方案
- 托管 SaaS:在 Jina AI 的 Embedding API 上获取免费密钥即可开始使用。
- 私有高性能部署:从我们的模型套件中选择模型,并在 AWS Sagemaker 上部署,即可开始使用。
将 Jina Embeddings 用于 RAG
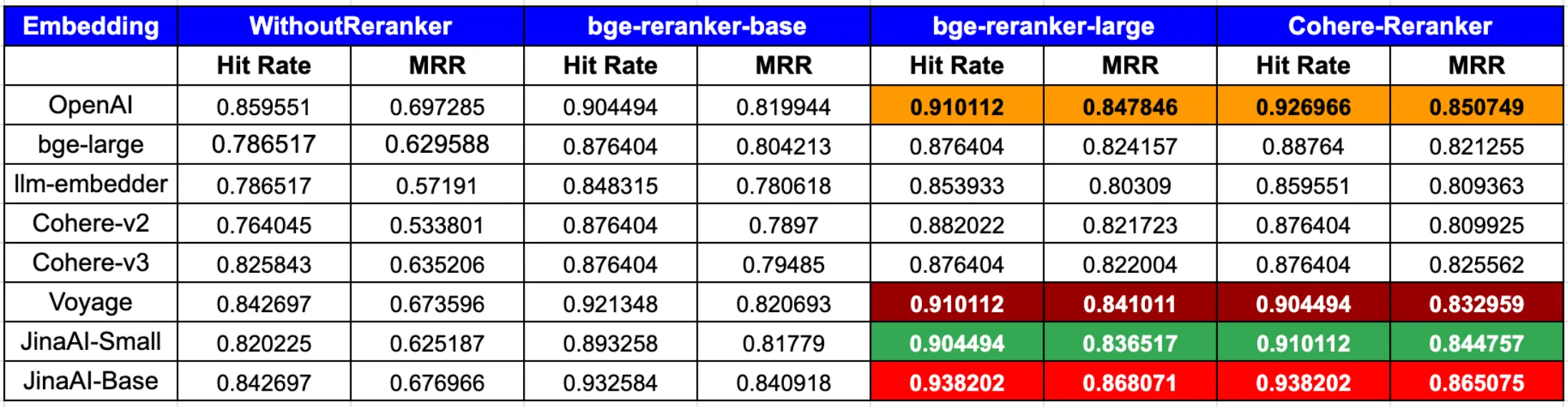
根据 LLamaIndex 最新的博客文章,
总之,要在命中率和 MRR 上都达到峰值性能,OpenAI 或 JinaAI-Base 嵌入模型与 CohereRerank/bge-reranker-large 重排序器的组合表现突出。
计划
- 支持更多欧洲和亚洲语言的双语嵌入模型,包括西班牙语、法语、意大利语和日语。
- 多模态嵌入模型,支持多模态 RAG 应用。
- 高性能重排序器。
故障排除
模型代码加载失败
如果在调用 AutoModel.from_pretrained 或通过 SentenceTransformer 类初始化模型时忘记传递 trust_remote_code=True 标志,您将收到无法初始化模型权重的错误。
这是由于 transformers 回退到创建默认的 BERT 模型,而不是 jina-embedding 模型导致的:
Some weights of the model checkpoint at jinaai/jina-embeddings-v2-base-en were not used when initializing BertModel: ['encoder.layer.2.mlp.layernorm.weight', 'encoder.layer.3.mlp.layernorm.weight', 'encoder.layer.10.mlp.wo.bias', 'encoder.layer.5.mlp.wo.bias', 'encoder.layer.2.mlp.layernorm.bias', 'encoder.layer.1.mlp.gated_layers.weight', 'encoder.layer.5.mlp.gated_layers.weight', 'encoder.layer.8.mlp.layernorm.bias', ...联系方式
加入我们的 Discord 社区,与其他社区成员交流想法。
引用
如果您在研究中发现 Jina Embeddings 有用,请引用以下论文:
@misc{günther2023jina,
title={Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents},
author={Michael Günther and Jackmin Ong and Isabelle Mohr and Alaeddine Abdessalem and Tanguy Abel and Mohammad Kalim Akram and Susana Guzman and Georgios Mastrapas and Saba Sturua and Bo Wang and Maximilian Werk and Nan Wang and Han Xiao},
year={2023},
eprint={2310.19923},
archivePrefix={arXiv},
primaryClass={cs.CL}
}