ViTMatte 模型
ViTMatte 模型在 Composition-1k 数据集上进行了训练。该模型由 Yao 等人在论文 ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers 中提出,并首次发布于 此仓库。
免责声明:ViTMatte 的发布团队未为此模型编写模型卡,因此此模型卡由 Hugging Face 团队编写。
模型描述
ViTMatte 是一种简单的图像抠图方法,旨在准确估计图像中的前景对象。该模型由一个 Vision Transformer (ViT) 和一个轻量级的头部组成。
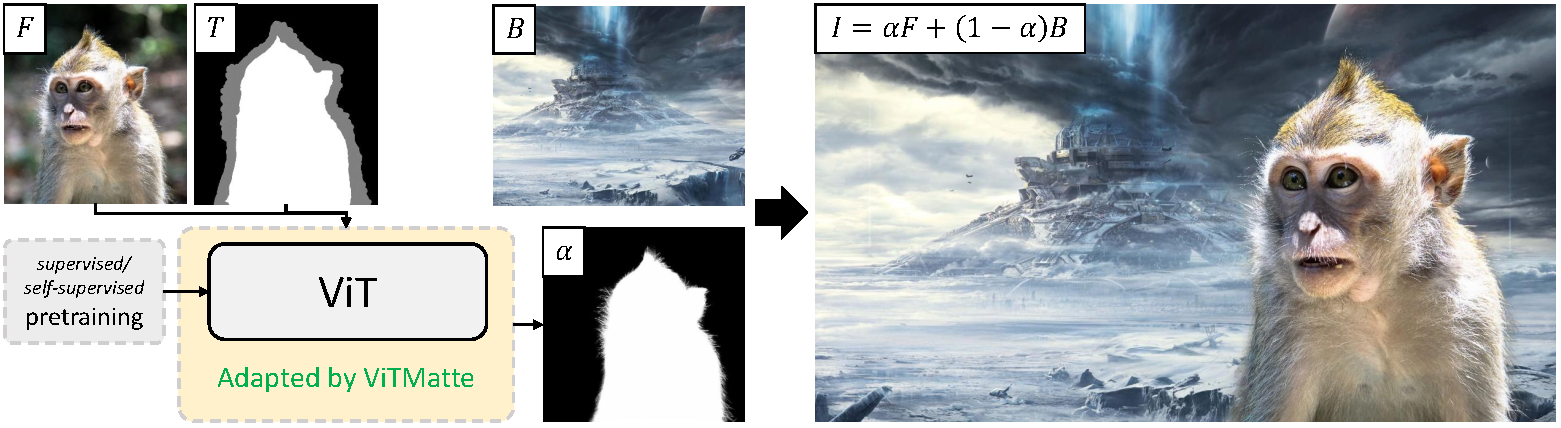
ViTMatte 的高层次概述。摘自 原始论文。
预期用途与限制
您可以使用原始模型进行图像抠图。请参阅 模型中心 查找其他可能感兴趣的微调版本。
如何使用
请参考 文档。
BibTeX 条目和引用信息
@misc{yao2023vitmatte,
title={ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers},
author={Jingfeng Yao and Xinggang Wang and Shusheng Yang and Baoyuan Wang},
year={2023},
eprint={2305.15272},
archivePrefix={arXiv},
primaryClass={cs.CV}
}当然,我会遵循您的要求,提供高质量的翻译服务。请提供您希望翻译的英文文本,我将会以通俗、专业、优雅且流畅的方式将其翻译成中文,并保持Markdown格式不变。