加入社区
 核心功能
核心功能让模型更易用,让创作更自由
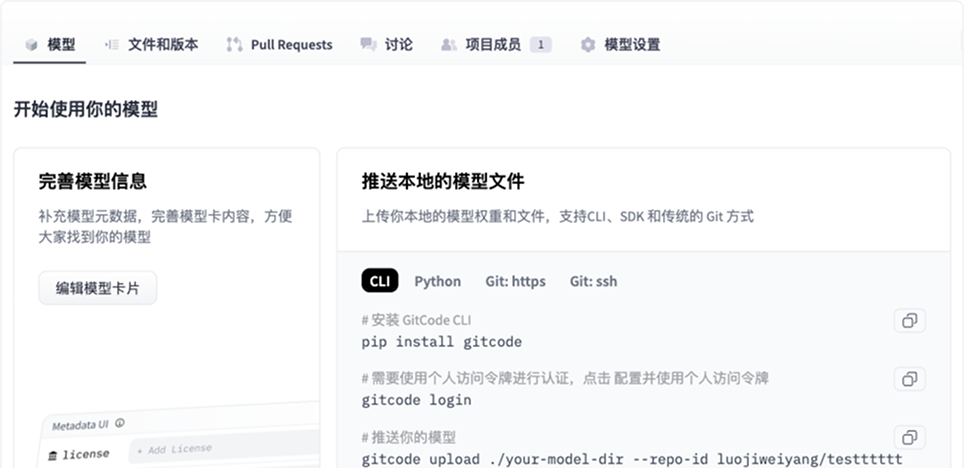
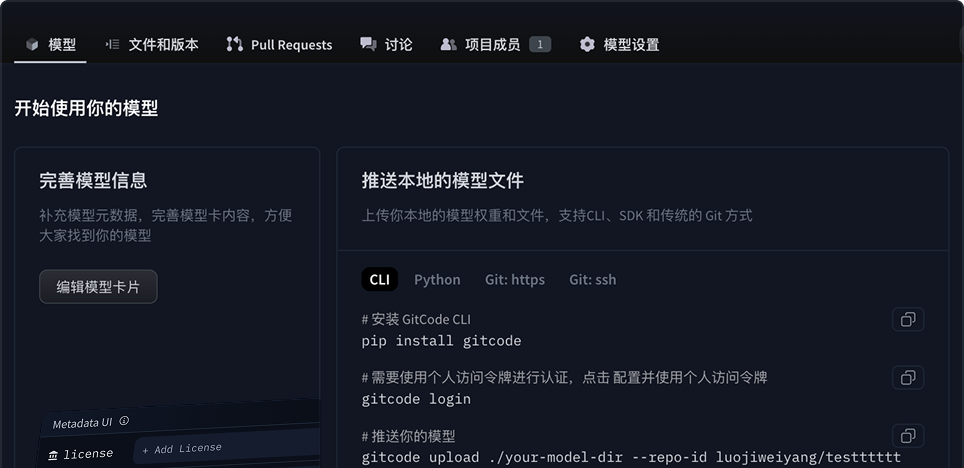
模型托管
安全托管,轻松版本化,让模型像代码一样流动


模型/数据集加速
全球分发,瞬间加载,让下载等待成为过去式,专注创新


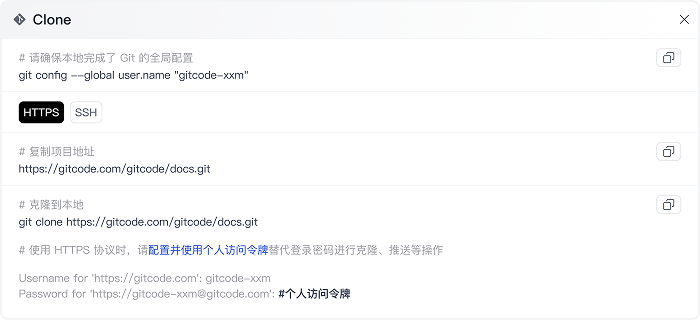
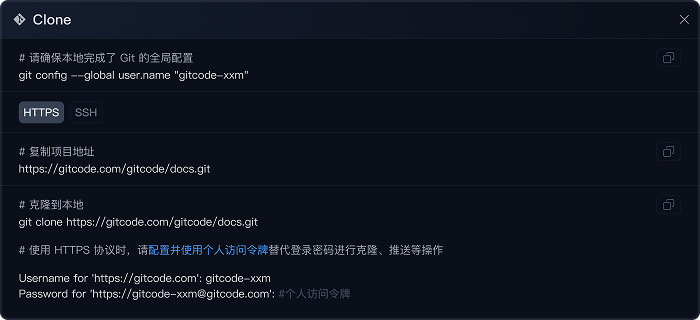
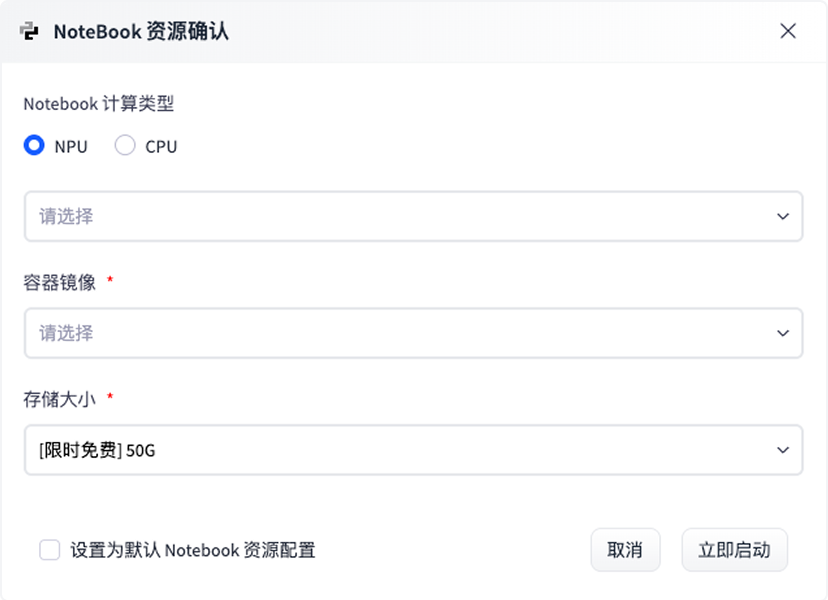
开发者个人工作台
一站式管理与展示,让 AI 创作更有序、更出彩


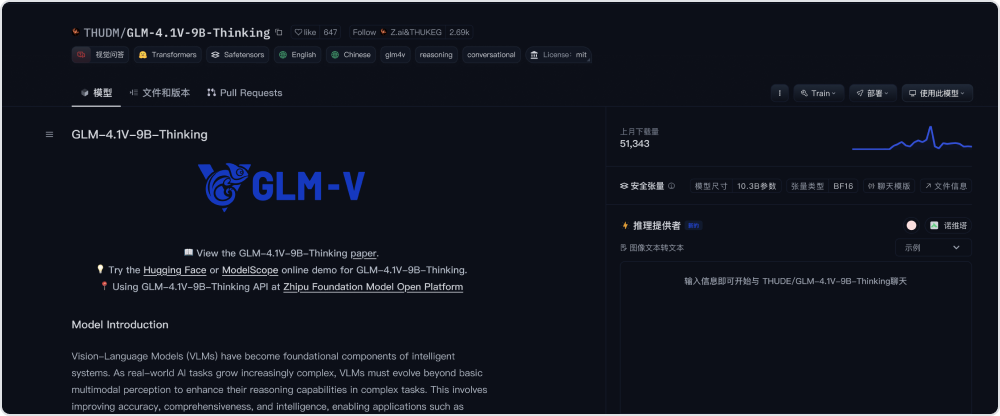
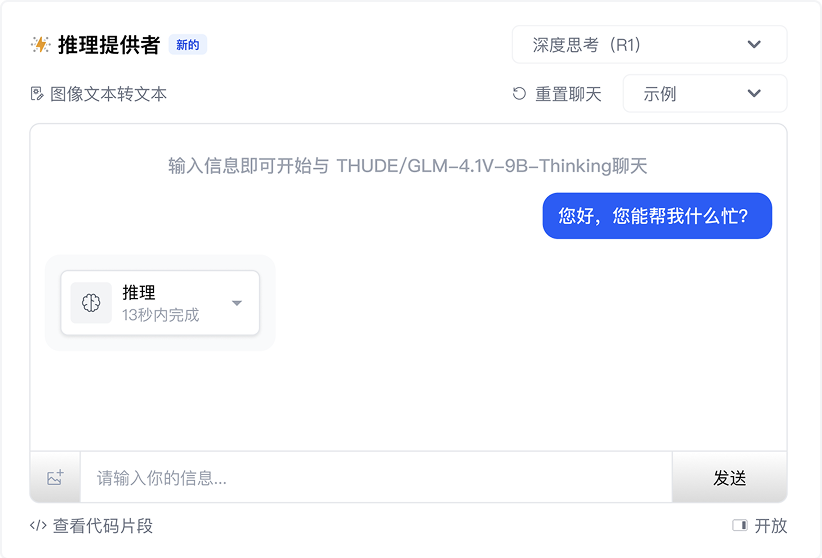
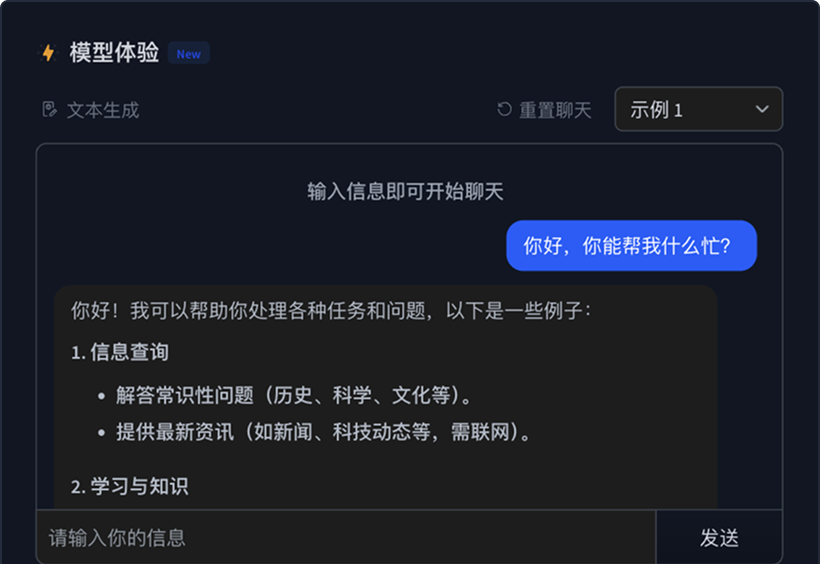
模型使用
多样化体验方式,随时随地解锁 AI 能力
社区活动
活力四射的开发者社区,挑战赛、协作项目与开放交流,让创意在共创中走向世界

 核心功能
核心功能让模型更易用,让创作更自由
模型托管
安全托管,轻松版本化,让模型像代码一样流动
模型/数据集加速
全球分发,瞬间加载,让下载等待成为过去式,专注创新
开发者个人工作台
一站式管理与展示,让 AI 创作更有序、更出彩
模型使用
多样化体验方式,随时随地解锁 AI 能力
社区活动
活力四射的开发者社区,挑战赛、协作项目与开放交流,让创意在共创中走向世界
 热门推荐
热门推荐发现、分享、部署最先进的AI模型、数据集和应用
GLM-5.2-FP8
可用于长文本处理、代码生成等长序列任务,具备100万token稳定上下文,支持多级别思考力平衡性能与延迟,采用IndexShare架构降低计算量,MIT许可完全开源无地域限制。
Kimi-K3
Kimi K3 是Kimi能力最强的模型:这是一个拥有 2.8 万亿参数的混合专家(MoE)模型,具备原生视觉理解能力,并支持 100 万 token 的上下文窗口。
Qwen3.6-27B-Fable-Fusion-711-Uncensored-Heretic-NM-DAU-NEO-MAX-MTP-GGUF
可用于提升通用智能、问题解决及指令遵循能力,适用于创意写作、角色扮演等场景。该项目是多阶段调优合并的开源模型,突破700 ARC-C基准,支持视觉功能,提供MTP和常规GGUF量化版本,兼顾性能与速度。
Intern-S2-Mobius
暂无描述
GLM-5.2
智谱开源 GLM-5.2,这是针对长文本任务的最新旗舰模型。相较于前代产品 GLM-5.1,它在长文本任务处理能力上实现了显著飞跃,并且首次在稳定的 100 万 token 上下文中提供这一能力。
